Data Is the Bottleneck in the Agentic Era
series: The Agentic Data Stack
- 1. Data Is the Bottleneck in the Agentic Era
- 2. Building the AI-Ready Data Platform

Everyone is talking about agents. Few are talking about what agents need to actually work.
The answer isn’t better models. It’s better data — and a lot more of it than most organizations are prepared to handle.
What an agent actually is
Before the argument, it’s worth grounding what I mean by “agent” — because the term has become dangerously vague.
Think of an agent as a qualified coworker operating inside a governed system. A coworker has an identity, specialized skills, access to tools, institutional knowledge, and — crucially — accountability.
Now imagine that coworker communicates in natural language, works 24/7, executes structured workflows without fatigue, and is fully observable and auditable. That’s an enterprise AI agent. Not autonomous chaos. Not a rogue decision-maker. A bounded, monitored, specialized system participant.
This framing matters because it changes what you optimize for. If agents are coworkers, they need the same things coworkers need: clear data, reliable tools, defined processes, and guardrails when they’re about to do something costly or irreversible.
With that frame in place — here’s the problem.
The two-sided data problem
On the input side, good data yields good agents. This has always been true for ML systems, but the stakes have shifted — from statistical noise to operational catastrophe.
In the dashboard era, a bad row in a data warehouse is a quality failure with a human buffer. An analyst might see a $10,000 anomaly in a report and — through expertise or neglect — adjust it or move on. Either way, the reasoning stays in the analyst’s head. The data tells you what happened, but the intent behind the decision is rarely logged.
Agents don’t have that luxury. They don’t have hunches. They don’t “look the other way.” A bad row feeding an agent triggers an autonomous refund, reroutes a shipment, or malforms a contract — instantly, at machine speed. The data layer must now provide the contextual skepticism that humans used to supply invisibly.
If you’re building agents, you’ve felt this even if you haven’t named it. Your agent works in the demo with clean sample data. In production, it hits stale records, ambiguous schemas, and tables that look right but aren’t. You blame the prompt. You tune the retrieval. But the root cause is upstream — the data feeding the agent was never built to serve an autonomous consumer.
On the output side, agents can produce far more data than humans do. Every decision trace, tool call, validation check, and retry generates telemetry. A fleet of agents can produce thousands of decisions per hour — each of which needs to be traced, audited, and fed back into the system. The data platform that was sized for human-speed workflows is suddenly undersized.
But the real issue isn’t just volume. Agent-generated data is qualitatively different from traditional machine data like server logs or clickstreams. It’s decision data — it requires near-real-time auditability, not just eventual consistency. In regulated contexts, it also raises retention, explainability, and access-control requirements that many legacy pipelines weren’t designed to meet. And it feeds back into the system that produced it, creating tight loops that traditional ETL architectures were never built for.
These forces create a feedback loop. Agents consume data to make decisions. Those decisions generate more data. That data feeds the next round of decisions. If the data layer can’t keep up — if ingestion is slow, transformations are brittle, or freshness guarantees are missed — the whole loop stalls.
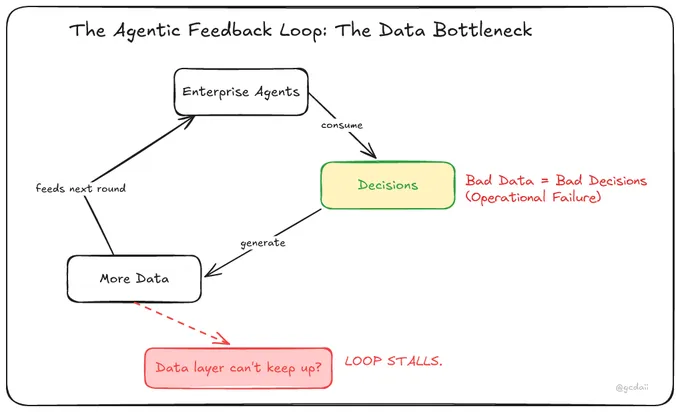
The constraint in the agentic era is shifting from model quality to data execution.
Why this isn’t obvious
Most of the conversation around agents focuses on the intelligence layer — which model to use, how to prompt it, how to chain reasoning steps. That focus is rational. Model quality was the primary bottleneck for adoption, and it remains important. The engineering work of building reliable agent orchestration, evaluation pipelines, and tool integrations is real and hard.
But models are improving fast, and access is democratizing. Once the intelligence layer reaches “good enough” — and for many enterprise tasks, it already has — the bottleneck shifts. The organizations that only invested in the intelligence layer hit a wall: the models are capable, but the data isn’t ready.
Here’s what makes this hard to see: the intelligence layer and the data layer aren’t independent systems. They’re symbiotic. The intelligence layer depends on the data layer for context, freshness, and correctness. The data layer now depends on the intelligence layer too — because agents generate decision data that flows back into the platform and shapes the next round. Each layer’s quality constrains the other.
When an agent builder spends days tuning a prompt to work around data that’s stale or ambiguous, that’s a symptom of the symbiosis breaking down. When a data engineer builds a pipeline without understanding that its consumers are now autonomous decision-makers, that’s the same breakdown from the other side.
The data layer doesn’t improve by itself. It requires deliberate engineering: streaming ingestion, schema contracts, SLA enforcement, cost governance, freshness guarantees. These aren’t glamorous problems. They don’t demo well. But they’re the difference between an agent that works in a notebook and an agent that works in production.
I’ve spent years building data platforms — lakehouse architectures, Spark pipelines, distributed compute systems. The engineering challenges in that world were about determinism: move data reliably from point A to point B, transform it correctly, make it available on time. The failures were predictable. A schema mismatch. A resource limit. A partition skew.
The agentic world inherits all of those challenges and adds new ones. Now the data platform doesn’t just serve dashboards — it serves autonomous decision-makers that operate around the clock and generate their own data exhaust that needs to be captured and processed in real time.
A concrete example
Consider Shiba Resorts — a Hawaiian resort that offers vacation packages, hotel bookings, spa experiences, and guided excursions. The platform captures reservation data, guest preferences, seasonal pricing, cancellation events, payment confirmations, and review sentiment.
Today, this data feeds dashboards and periodic ML models. The data team builds pipelines, ensures freshness, manages cost. It works.
Now add agents. A pricing agent that adjusts package rates in real time based on demand signals and seasonal patterns. A fraud agent that flags suspicious bookings before payment clears. A personalization agent that tailors package recommendations per guest — factoring in past stays, dietary preferences, activity interests. A concierge agent that answers guest questions and suggests excursions based on weather and availability.
Each of these agents consumes data from multiple pipelines. Each produces its own decisions and telemetry. The pricing agent alone might make thousands of adjustments per hour — every one of which needs to be logged, validated against business rules, and made available for downstream analysis.
The data volume didn’t just increase. It changed in character. It’s higher velocity, higher stakes, and bidirectional — agents both read from and write to the data layer.
The platform team that was managing batch pipelines with hourly SLAs is now operating the runtime that agents depend on. If they can’t scale the data layer to match, the agents stall — and the business loses the very advantage it was trying to build.
The structural shift
Zoom out. In an agentic enterprise, the intelligence layer has real scaling challenges — cost, latency, evaluation — but the trajectory is clear: models get better, access gets cheaper, and orchestration frameworks mature. The data layer scales differently. It requires engineering, investment, and architectural decisions that compound over time. There are no shortcuts.
The organizations that recognize this asymmetry early will have a structural advantage. Not because they have better models — everyone will have access to roughly the same models — but because they have a data platform that can feed agents reliably and absorb the data those agents produce.
This isn’t an argument that the data layer matters more than the intelligence layer. It’s an argument that they rise and fall together — and right now, the data layer is the one being underinvested.
Agents don’t remove humans. They remove bottlenecks and repetitions.
And the primary bottleneck in the agentic era will be data execution.
This is Part 1 of a two-part series. In Part 2, I lay out what an AI-ready data platform actually looks like — and why the lakehouse architecture is the natural foundation for the agentic era.
Updated March 2026 to strengthen the framing around the symbiotic relationship between data and intelligence layers.
continue reading
Building the AI-Ready Data Platform
Agents don't fail because the model is wrong. They fail because the data platform wasn't built for them. Here's what an AI-ready data layer actually looks like — and proof it works.
Your Code Survives the Session. Your Reasoning Doesn't.
A practical guide to building a personal journaling system for AI-assisted development — using Claude Code skills and hooks to capture the reasoning that code alone can't preserve.
Starting Over, on Purpose
Why I rebuilt this site from scratch — and what I plan to explore next.